

 Android & iPhone
Android & iPhone5分钟让AI成为你的第二大脑

区块律动BlockBeats
刚刚
作者:AI Edge;编译:Peggy,BlockBeats
本文介绍了一种基于 Claude Code 与 Obsidian 搭建的个人知识系统,其核心不再是传统 RAG 模式下「每次查询、临时检索」的用法,而是尝试让 AI 持续构建并维护一个可演化的知识库(Wiki)。
从结构上看,该系统可以拆分为三层:
·其一,是原始数据层,包括笔记、文章、转录内容等不可修改的输入源;
·其二,是由 AI 维护的结构化知识库,在持续更新中完成交叉引用与关系构建;
·其三,是 Schema 规则层,用于规范知识的组织方式与系统运作逻辑。
围绕这一结构,系统通过三类核心操作运行:Ingest(摄取),将外部信息不断纳入体系;Query(查询),实现对知识的即时调用;Lint(校验),用于检查结构一致性并修复潜在问题。
在这一机制下,知识不再停留于一次性对话结果,而是通过「写入—整理—再利用」的循环,逐步沉淀为可复用的长期资产。作者据此提出,这种模式使知识具备类似「复利」的积累效应:一方面减轻个体的认知负担,另一方面提升模型输出的准确性与上下文一致性。
但这一系统的有效运行,也建立在一个前提之上——持续输入与维护。如果缺乏稳定的数据注入与结构更新,这一「第二大脑」将难以形成真正的积累效应,其优势也将随之减弱。
以下为原文:
Claude Code + Obsidian,是我用过最强大的 AI 组合。
我几乎搭建出了一个「AI 第二大脑」,把我所有的思考、阅读、写作、线上研究等内容都纳入其中。这里面包含了我的商业计划、我发布过的所有 YouTube 视频、写过的文章,以及一切对我重要的内容。
Claude Code + Obsidian 已经在各个平台上迅速走红,而且这并非偶然。
对我个人来说,这套 AI 系统极大地减轻了我的认知负担,让我能够把精力集中在真正重要的事情上——无论是业务,还是个人生活。

我的 Claude Code + Obsidian 系统
这套系统看起来也许有点复杂,但实际上搭建只需要 5 分钟。更关键的是,它自带记忆机制,会随着使用不断自我优化。
接下来,我会一步一步带你复刻这个「AI 第二大脑」系统,它确实能实实在在地提升你的效率。
建议你读到文章最后——我会附上一份完整的 Claude Code + Obsidian 操作速查表,以及文中提到的所有资源(全部免费)。
开始之前
这套系统并非我一人原创,它的灵感来自 Andrej Karpathy 几天前关于「LLM 知识库」的一条爆火推文。
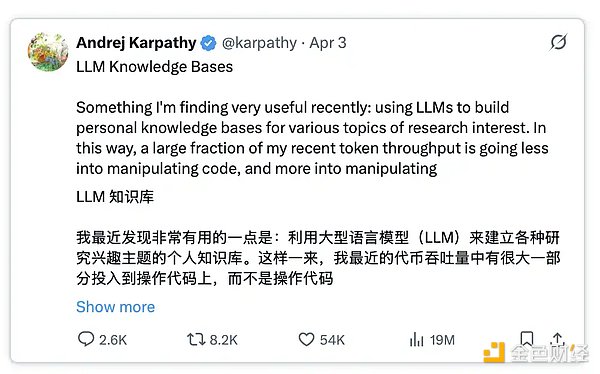
相关阅读:https://x.com/karpathy/status/2039805659525644595
这条推文之所以迅速走红,是因为它为解决当前 AI 发展中的一个关键痛点提供了思路。
这个问题就是:每当你开启一段新的对话,或者切换到新的 AI 工具时,都不得不反复重新输入提示词、补充上下文,几乎等于从零开始。
而将这一套系统提示词,与 Obsidian 和 Claude Code 结合起来之后,这个问题可以被彻底解决,同时还能显著提升 AI 的输出质量。
这个系统是如何运作的?
整个系统由四个核心模块构成:
1、你的数据:包括文章、笔记、转录内容、灵感想法等
2、组织方式:通过 Claude Code 在 Obsidian 中自动完成整理
3、即时调用:你可以随时向这个「数据库」提问,获得答案
4、进化记忆:系统会随着使用不断变得更聪明
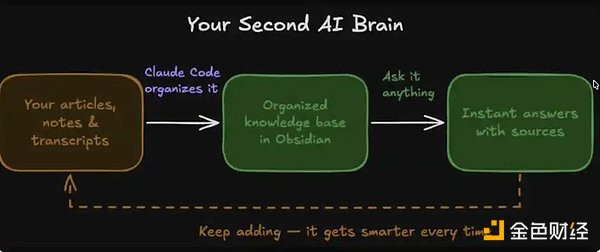
你的 AI 第二大脑
这套系统的真正力量在于什么?
作为人类,我们的认知带宽是有限的。我们会遗忘,有时也很难把不同的想法连接起来,能同时跟踪和处理的信息终究是有上限的。
而借助这套由四个模块组成的系统,你实际上是在释放自己的认知负担,把「连接、整理与理解信息」的工作交给 Obsidian 和 Claude Code。
你的想法开始被系统性地串联起来,一条笔记可以自动关联到另一条笔记,而你可以随时通过 Claude 将这些内容重新提取、组合和调用。
在这种结构下,你的知识不再是零散的,而是一个可以被不断调用和重组的网络——几乎没有上限。
如何在 5 分钟内搭建你的 AI 大脑
1、下载 Obsidian
官网: https://obsidian.md/
https://obsidian.md/
2、创建你的 Vault(知识库)
下载完成后,Obsidian 会提示你创建一个「Vault」。
你可以把它理解为电脑上的一个文件夹,我们会在这里存放所有内容,并让 Claude Code 访问和管理这些数据。
这个 Vault 的名称可以随意设置——比如我自己就叫它「Obsidian Vault」。
Obsidian Vault(知识库)
这个 Vault,就是 Obsidian 用来存储你所有数据与笔记的地方,所有内容都会以 MD(Markdown)文件的形式保存。
3、设置 Claude Code
接下来,你需要配置一个可以访问 Claude Code 的方式。对我来说(也很可能对大多数人而言),最简单的方法就是直接使用桌面客户端。
在主聊天界面中,点击「Select Folder(选择文件夹)」,然后找到你刚刚创建的 Obsidian Vault 并选中它即可。
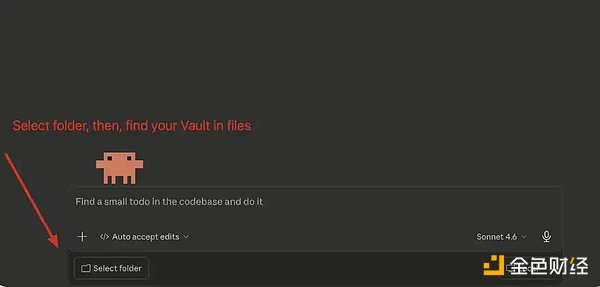
Claude Code:连接你的 Vault
4、设置系统提示词(System Prompt)
当你选好文件夹之后,下一步就是把 Andrej Karpathy 的系统提示词粘贴到主聊天框中。
你可以在这里复制这段提示词:https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f

你的输入应该是这样的:
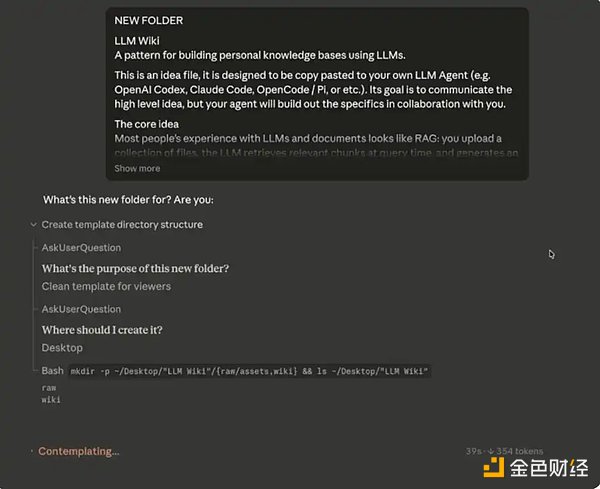
Claude Code 初始输入
小提示:如果你不想,也完全可以不用手动打开 Obsidian。只要把 MD 文件夹(也就是你的 Vault)以及相关数据交给 Claude Code,它就可以直接对这些文件进行读写和修改——而这些内容会自动同步到你的 Obsidian「第二大脑」中。
5、构建你的数据库
当你输入完上述的系统提示词之后,Claude Code 会开始向你询问一些数据来源,用来初始化并逐步填充你的「第二大脑」。
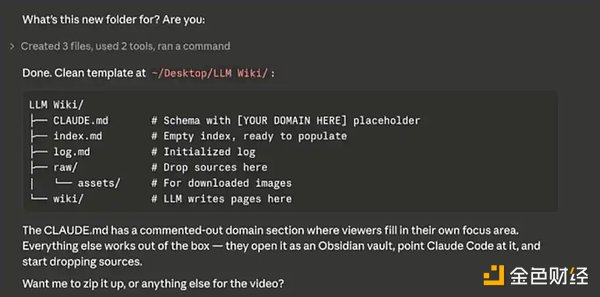
构建你的数据库
你可以把 Obsidian 想象成一本「空白笔记本」——一开始需要你主动输入内容,数据库才会逐步建立起来。可以导入的内容包括:笔记、CSV 文件、Markdown / 文本文件等。
一些实用建议:
·从你现有的笔记工具中导出数据
·如果你使用 Notion,可以导出为 CSV 文件
·让 Claude(或其他大模型)整理一份关于你的信息,用来初始化你的「第二大脑」
·把你已有的文章、收藏、灵感想法等一次性导入进来——这是建立初始数据的最好时机,后续也可以随时补充
需要注意的是,像我这样数据量较大的数据库,并不是一蹴而就的,而是随着时间不断输入、逐步积累形成的。

我的数据库
就是这样,你的「AI 第二大脑」已经搭建完成,可以开始运行了。接下来,我再分享一些进阶技巧,帮你把它用得更高效。
进阶技巧(Pro Tips)
1、Obsidian Chrome 扩展插件
如果你想更轻松地往系统里添加数据,只需要安装 Obsidian 的 Chrome 扩展。它可以让你在浏览网页时,直接点击「Add to Obsidian(添加到 Obsidian)」,把内容一键保存进你的知识库。这会让你构建「第二大脑」的过程变得非常顺手。
我自己也经常用这个功能来收集文章、网页数据、研究资料等等。
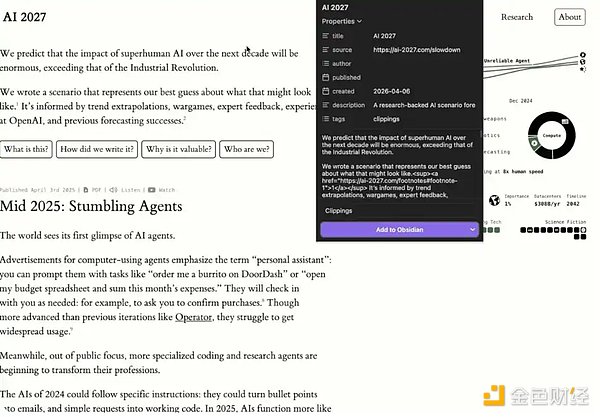
示例:使用 Obsidian Chrome 扩展
需要注意的是,通过扩展添加的数据,最初只是一个「孤立的数据源」。
接下来你可以告诉 Claude Code:「我刚刚在 Obsidian 里添加了 [x],请帮我把这些内容整合进我的 Wiki。」
Claude Code 会自动将这些新数据与已有内容建立关联、生成链接,让它真正融入你的「第二大脑」。这也是这套工具组合强大的原因所在。
2、分开建立文件夹(Vault)
Andrej Karpathy 建议使用两个独立的文件夹(Vault):
·一个用于工作 / 商业内容
·一个用于个人生活 / 目标管理
我自己的使用体验也是,这样的结构最清晰、最有效。
3、实用性
我发现这套系统最有价值的一个用法,其实很简单:让你的 LLM 提示词更精准。
当模型可以访问你完整的个人信息、商业计划、写作背景等上下文时,它就能生成更加「定制化」、更贴近现实情况的高质量提示词(甚至是「超级 Prompt」)。
当然,这套系统的用途远不止这些,但如果你只想从一个最实用的场景入手,我会强烈建议你先从「提升 Prompt 质量」开始。
4、Orphans(孤立节点)
在 Obsidian 中,「Orphans」指的是那些没有与其他笔记建立连接的数据点。
这个功能很有用,因为它可以帮你:
·找到尚未被整合的想法
·发现数据库中的「薄弱区域」
·判断哪些内容值得进一步扩展或深化
换句话说,它不仅是一个整理工具,也是一个帮助你发现思考盲区的机制。

Orphans(孤立节点)
你可以在右上角点击「三个点」,找到并开启 Orphans 的开关,用来查看哪些内容还没有建立关联。
这套系统的潜在缺点
前面我们已经讲了很多优点、使用场景和优化方法,那么它的不足是什么?什么情况下你不太适合使用这套系统?
1、不习惯可视化的人
这套系统的一个核心优势,是可以将数据进行可视化呈现。如果你本身并不依赖或不习惯这种方式,那它对你的帮助可能会比较有限。
2、需要一定维护成本
如果你不愿意持续维护一个数据库,那这套系统可能不适合你。虽然维护成本并不高,但如果不持续往「第二大脑」中输入数据,它就很难发挥价值。
3、存储占用
所有内容都会以 Markdown 文件的形式存储在本地,这会占用一定的设备空间。这一点也需要提前考虑。
 0
0
声明:本文由入驻金色财经的作者撰写,观点仅代表作者本人,绝不代表金色财经赞同其观点或证实其描述。
提示:投资有风险,入市须谨慎。本资讯不作为投资理财建议。

24小时热文
 特朗普家族加密项目 WLFI 陷 FUD
特朗普家族加密项目 WLFI 陷 FUD比推 Bitpush News
 香港这场“阳谋”的真正目标——从来不是稳定币
香港这场“阳谋”的真正目标——从来不是稳定币Web3小律



 AI 会选择哪条链?悬念待解
AI 会选择哪条链?悬念待解比推 Bitpush News
 香港首批稳定币牌照花落汇丰与渣打 热门申请者全线落选
香港首批稳定币牌照花落汇丰与渣打 热门申请者全线落选Barrons巴伦

 加密银行竞争的关键是什么?
加密银行竞争的关键是什么?金色精选

 5分钟让AI成为你的第二大脑
5分钟让AI成为你的第二大脑区块律动BlockBeats
- 寻求报道
- 金色财经APPiOS & Android
- 加入社群
Telegram - 意见反馈
- 返回顶部
- 返回底部