

 Android & iPhone
Android & iPhone智能体崛起后 整个AI价值链的分布都变了

追风交易台
刚刚
AI投资的主叙事正在经历一次结构性迁移。摩根士丹利最新研究指出,随着AI从“生成内容”走向“自动执行任务”,下一轮AI基础设施的增量逻辑将从“单芯片算力竞赛”扩展为“全栈系统工程”——GPU依然是核心,但不再独享预算与溢价。
据追风交易台,摩根士丹利研究部分析师Shawn Kim在报告中直接写道,“智能体AI标志着从计算到编排的结构性转变。”在智能体工作流中,CPU侧编排时间可占总时延的50%至90%,由此推导出到2030年新增325亿至600亿美元的CPU增量市场空间,并将服务器CPU总TAM推至825亿至1100亿美元量级。
与此同时,DRAM、ABF载板、晶圆代工、存储、连接器与被动元件等环节,均将从“配角”跃升为新的瓶颈与利润池。将在2030年额外催生15至45EB的DRAM需求,规模相当于2027年全行业年供给的26%至77%。
这一判断对市场意味着:AI资本开支的受益者将从少数芯片巨头扩散至整条全球供应链,下一轮超额收益,可能更多来自那些在智能体工作流中最先成为瓶颈、且最难快速扩产的"使能环节"。随着瓶颈在不同环节迁移,AI价值链的权重分布随之改变。
从“生成”到“行动”:智能体把瓶颈从算力推向编排
生成式AI的典型工作流结构相对简单:用户请求到达后,CPU完成少量预处理,GPU负责token生成,随后返回结果。整个链路中,GPU是绝对主角,CPU仅承担辅助功能。
智能体的运作逻辑截然不同。完成一个任务,系统需要经历规划、检索、调用外部工具与API、执行、反思迭代等多个步骤,还涉及多智能体协作、权限管理、状态持久化与调度等大量“控制面”能力。大摩的核心结论是:智能体带来的不是更"重"的单次推理,而是更多步骤、更多状态、更多协调,而这些工作天然更适合CPU处理。
由此带来两个直接后果:其一,集群层面CPU与GPU的配比将系统性上升;其二,DRAM从“容量配置项”升格为“性能与吞吐的核心系统组件”。数据中心的瓶颈将越来越多地出现在内存带宽、数据搬运、互连时延与系统级协调,而非单纯的GPU算力。
CPU配比正在重估:从"1:12"走向"1:2"乃至反转
过去,"1颗CPU服务约12块GPU"曾是AI服务器的典型架构描述。但报告指出,随着智能体工作流变长、工具调用与上下文管理趋于复杂,这一比例正在快速收窄。
以NVIDIA路线图为例,更新估算显示:在Rubin平台附近,CPU与GPU的配比已接近1:2;若向Rubin Ultra等更激进形态演进,甚至可能出现2颗CPU对应1颗GPU的反转配置。即便仅从1:12改善至1:8,对超大规模部署而言,CPU的绝对需求量也将出现量级跳升。
一旦这一方向成立,CPU的需求弹性将从“跟着服务器出货走”转变为“跟着智能体复杂度走”,这意味着CPU需求的增长将更具结构性,而非仅仅是传统硬件换代周期的延续。

CPU TAM重算:2030年825亿—1100亿美元,增量来自编排
摩根士丹利采用“系统分层”方法,将智能体带来的CPU机会从传统服务器更新换代逻辑中剥离,建立三个独立分析口径:
Head Node CPU
对应贴近GPU系统的机架控制层,以2030年全球约500万颗AI加速器、每颗加速器配2颗高端CPU、CPU平均售价约5000美元为假设,对应约500亿美元TAM。
Orchestration CPU
覆盖智能体编排新增需求,包括规划与调度、工具链、RAG管线、KV cache与向量库相关内存服务、策略与可观测性等。算额外新增1000万至1500万颗CPU、ASP约3000美元,对应300亿至450亿美元TAM。
Other CPU
涵盖存储节点、部分网络节点等,对应约25亿至150亿美元。

三项合计,2030年服务器CPU总TAM约825亿至1100亿美元,其中智能体带来的增量约325亿至600亿美元。整个测算的底层锚点是对2030年全球AI数据中心基础设施销售额约1.2万亿美元的判断(2025年约为2420亿美元)。
报告同时给出了“上修开关”:若按NVIDIA口径,2030年AI基础设施销售额达到3万亿或5万亿美元,则CPU TAM区间将被整体推至2060亿至2750亿美元,乃至3440亿至4580亿美元。这并非基准预测,但揭示了"AI工厂"规模扩张对CPU需求的系统性放大效应。
内存从配角变主线:2030年新增DRAM需求15至45EB
智能体的真正差异化不只在推理能力,更在“可持续的上下文与记忆”。持续上下文、KV-cache、工具调用中间态与并发智能体工作集,CPU侧DRAM实质上成为HBM的功能性延伸。
测算模型直接明了:新增DRAM需求等于新增编排CPU数量乘以单CPU平均DRAM配置。两档假设分别为:新增1000万颗编排CPU、每颗配置约1.5TB;偏乐观情形为1500万颗、每颗约3TB。由此推导出2030年智能体可带来15至45EB的新增DRAM需求,相当于2027年DRAM行业年供给的26%至77%。
在周期判断上,报告还注意到一个市场结构变量:多数内存供应商正在与大客户讨论3至5年长期协议(LTA),这可能令定价下行斜率趋缓,并将2027年前的盈利能见度抬高。“内存层级正在成为AI系统的核心变现路径"——主机DRAM、内存接口芯片、CXL扩展及SSD/HDD分层存储,都将成为更可持续的价值承接点。

供给越紧的环节越具定价权:ABF载板、代工与使能组件
而真正具备超额收益潜力的,是那些"产能扩得慢、验证周期长"的使能环节。报告重点点名了以下几条链:
ABF载板:这轮AI驱动的ABF上行周期可能延续至本十年末,2026至2027年附近存在供需缺口风险。仅"CPU TAM扩大"一项,就可能带来2030年ABF需求5%至10%的上修;其中服务器CPU ABF载板市场到2030年约达47亿美元,CPU带来的增量需求约12亿美元。

晶圆代工(尤其先进制程):CPU代工可服务市场2026年约330亿美元,2028年约370亿美元。台积电在CPU代工领域的份额预计从2026年约70%进一步提升至2028年的约75%;并预计英特尔可能在2027年下半年开始将服务器CPU外包给台积电。
BMC与内存接口:Aspeed被强调为CPU服务器BMC的核心受益者,其在该细分领域约有70%的市场份额,新一代AST2700平台带来40%至50%的ASP提升空间;Montage则被置于"内存互连"价值链,全球收入份额约36.8%。
CPU Socket与被动元件:报告以Lotes与FIT作为CPU socket的直接映射,测算每增加100万颗CPU需求,Lotes收入约增加0.6%、FIT约增加0.2%(仅按socket口径计)。被动元件方面,以"每台通用服务器约30美元MLCC内容量"为简化假设,推算出2030年额外5亿美元MLCC需求增量,约占届时全球MLCC市场的2%至3%。
CPU是最清晰增量,但"使能环节"更受偏爱
报告承认智能体工作负载增长将结构性利好AMD的云端份额,但对AMD与英特尔均维持Equal-weight评级,倾向于通过NVIDIA、博通等“资本开支与token增长更直接映射至盈利”的标的来追踪智能体主题,同时将估值约束列为重要考量维度。
从更宏观的框架看,这份报告的核心价值在于将AI的投资范式从“单点算力军备竞赛”升级为“系统效率与瓶颈经济学”:GPU是发动机,CPU是变速箱与控制系统,内存与互连是油路与底盘——单点极致仍重要,但决定规模化回报的是整车协同。
对产业链而言,这意味着AI投资的超额收益来源将更加分散也更为长期:不只来自“最强GPU”,更来自那些在智能体工作流中率先成为瓶颈、且最难快速扩产的环节。能够持续追踪的高频验证指标包括:新平台BOM中CPU数量与内存配置的上修幅度、云厂商长期协议签约节奏,以及ABF载板与先进制程产能的利用率走势。
 0
0
声明:本文由入驻金色财经的作者撰写,观点仅代表作者本人,绝不代表金色财经赞同其观点或证实其描述。
提示:投资有风险,入市须谨慎。本资讯不作为投资理财建议。
24小时热文

 当收益耗尽
当收益耗尽Block unicorn





 为什么今天必须重看美国稳定币
为什么今天必须重看美国稳定币沙丘路的毛圈狮子
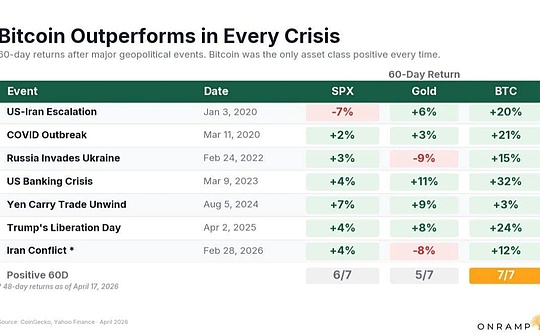 比特币已成为避险资产之王
比特币已成为避险资产之王金色财经
 智能体崛起后 整个AI价值链的分布都变了
智能体崛起后 整个AI价值链的分布都变了追风交易台

 5分钟撤出3亿美金 孙宇晨的逃生术堪称教科书级别
5分钟撤出3亿美金 孙宇晨的逃生术堪称教科书级别GoMoon
- 寻求报道
- 金色财经APPiOS & Android
- 加入社群
Telegram - 意见反馈
- 返回顶部
- 返回底部