

 Android & iPhone
Android & iPhoneAnthropic 如何打造下一代 Claude

硅星GenAI
刚刚
Anthropic研究PM Alex Albert最近接受访谈,第一次从内部视角讲清楚了下一代Claude是怎么被“做”出来的。几个关键信息:每个新模型在构思阶段就有明确的产品需求——这一代要擅长什么、要修复上一代的哪些问题,但在训练真正跑起来之前,谁也不知道最终能力分布会是什么样。用户反馈进来之后,他们用Claude帮自己聚类、提炼主题、生成评测用例,形成一个“用AI改进AI”的闭环。Claude最近有了“自适应思考”能力——模型自己判断一个问题值不值得多想,而不是全靠用户手动开关。更有趣的是,Claude开始在后台“做梦”,整理记忆、发现矛盾、清理冗余,这类似于人类的记忆巩固过程。另外Claude的性格不是靠提示词设定的,而是通过大量训练、让Claude自评、研究员反复阅读对话逐步培养出来的。Alex认为,随着AI长时间自主运行、在无人监督的情况下做出大量判断,它的“品格”将愈发重要。他还透露,Anthropic已有团队全职研究“Claude是否具备意识”,虽然尚无结论,但研究过程本身已经帮助团队让Claude的行为更可预测、更值得信赖。以下是访谈全文。
每一代新模型,Anthropic 都是按产品来做的
主持人: 很高兴今天请到你。你之前做过开发者相关工作,最近又转去研究团队做产品经理。产品经理在研究团队里到底怎么工作?我其实很难想象。
Alex: 本质上和产品经理做的事很像。还是要尽可能贴近用户、和客户交流。在 Anthropic,我们会在某种程度上把模型本身当作一个产品。每一代新模型开始前,我们都会先定义:这代模型到底要擅长什么?我们希望它在哪些方面做得更好?和普通产品开发不一样的地方在于,模型开发有点像“把一个东西养出来”。我们会基于训练方法、架构选择和一些技术判断,对它最终会擅长什么有直觉,但在真正训练出来之前,谁也不可能完全知道。研究 PM 从模型最早的构想到训练,再到最后发布,都会一路跟下来。编码一直是非常重要的一类能力,知识工作也是最近特别重要的一类。我们最近几代模型也在强化一些更具体的使用场景,比如在产品里处理表格、做 spreadsheets 之类的能力。
除此之外,每一代模型还要去修补上一代做得不够好的地方。所以我们会去和客户交流,了解这代模型在哪些地方表现很好,哪些地方会掉链子。如果我们发现一些很有意思的行为,也会想:下一代训练时,有没有什么干预方法可以把它往更好的方向推。这里说的“客户”,既包括内部团队,也包括外部所有使用 Claude 的人。因为模型会触达太多不同的使用面。作为研究 PM,你得考虑这个模型最终会通过哪些界面接触用户:API、Claude Code、CoWork,或者其他产品入口。模型和产品其实是混在一起塑造用户体验的。不同入口会有不同提示词、不同使用方式、不同任务形态,这些都会影响用户最终感受到的模型表现。好在我们有很多非常优秀的研究员,他们分别盯着不同能力方向。另外,用户反馈系统也很重要,否则反馈量会像消防水管一样直接冲过来。这几年我做这个角色,一个很明显的变化就是:我们越来越多地用 Claude 来帮助 PM 自己工作。比如处理大量用户反馈时,Claude 对我帮助非常大。它可以帮我们把反馈聚类、提炼主题,还可以把某类问题先合成出一个“典型问题版本”,看看能不能进一步做成 eval,或者变成别的诊断手段,帮助我们真正弄清楚问题出在哪里。
把自适应思考植入 Claude
主持人: 能不能举个具体例子?
Alex: 一个很典型的例子,就是我们怎么处理新功能反馈。最近几代模型里,一个新功能叫 adaptive thinking,也就是“自适应思考”。在此之前我们有 extended thinking,意思是你一打开,模型就会进入更长的思考模式。而自适应思考不一样,它让模型自己决定什么时候该想,什么时候不该想。有些问题很复杂,需要先规划、先推理,模型就应该多想;有些问题没那么复杂,它就没必要花太多 token。这个功能我们一直在一代一代地调。用户的反馈非常关键,因为我们特别在意:Claude 到底有没有在对的场景里做对的思考?用户真希望它多花 token 的问题,它到底有没有触发更深的思考?
主持人: 我特别有共鸣。有时候它对我的人生问题回得太快,我反而会有点失望,觉得你怎么都不多想一下。
Alex: 对,问题就在这里。一个问题该不该“多想”,其实很依赖上下文。比如一个完全不认识的人突然问我“我现在该做什么”,我可能只能很快给个比较泛的建议,因为我根本不了解他。但如果是你来问,而我知道你是谁、在乎什么、以前做过什么,那我就会认真多想,因为我得考虑什么样的答案才真的适合你。模型也是一样。如果它还没有建立起对用户的理解,没有形成关于这个用户的心理模型,那它就很可能会误判:这个问题到底值不值得深想。因为它其实并不知道。
Claude 的记忆,开始有点像在“做梦”
主持人: 这个说法太对了。那你们是不是也在做 Claude 的记忆功能?

Alex: 记忆当然是研究侧很重要的一块。不同产品面的记忆实现方式不完全一样。比如在 Claude.ai 里,它会把信息写进一个 memory file 里。然后系统会在夜间重新处理这些记忆,做修剪和整理。我们最近也把类似机制用在了 managed agents 上。我们现在在研究一个很有意思的概念:dreaming,也就是“做梦”。人类做梦到底有什么作用,其实现在也没有完全定论。但有一种说法是,它可能和记忆的重新整合有关。我们就在想,能不能把类似过程带到 Claude 的记忆里。也就是说,当 agent 没有在替你执行任务,或者只是后台挂着的时候,它会重新回看自己的记忆,找出里面可能互相矛盾的地方,把它们修剪掉、整理干净,相当于做第二轮处理。我觉得这件事特别有意思。
主持人: 我自己的做法是,我以前会专门写一个 Google Doc,总结我的生活状态:家里是什么情况、孩子叫什么、什么事让我有能量、什么事让我没能量。然后把这份文档挂到 Claude 项目里。这样一来,它回答我的问题就会好很多。但你说的默认记忆机制,听起来有点像它每天晚上会整理一遍?
Alex: 大体上可以这么理解。对,差不多就是总结、梳理、去冲突。
现在做产品,真正贵的只剩“单向门决策”
主持人: 说回产品管理。你之前提到,你总在找最新的瓶颈。那现在整个产品开发流程里,哪里已经被大幅提速了,哪里还是瓶颈?

Alex: 过去二十年,软件交付流程其实没有本质变化。大家只是不断做一些局部优化,比如 sprint、规划流程、组织结构这些。但真正把开发周期压缩下来的,是最近这一两年。现在做一个东西的成本和时间都已经低很多了。你可以很快拉起原型,甚至在一天里做出一个初始 MVP,而不是像以前那样要两三周甚至更久。这会反过来改变整个产品开发生命周期。对 PM 来说,问题就变成:我现在写 PRD、估工作量、列需求时,到底还要怎么规划?有时候你会发现,很多旧方法其实已经有点浪费时间了。要看项目。有些项目确实还是要做更多考虑,这和项目范围、复杂度有关。
但我们现在最关心的问题通常是:哪些决策属于 one-way door,也就是单向门决策、不可逆决策。这些才是最值得花时间的地方。如果一个东西不是单向门,做了还能回滚,那它现在基本就已经很便宜,甚至几乎等于免费。因为工程时间本身,今天已经不像以前那样是高成本、不可逆的资源了。但如果一个决定会影响最终用户体验、会影响后续长期判断,或者涉及到必须购买和投入的物理资源,那就很难回头。这种事我们就会花更多时间。比如新模型预训练前,先选定模型架构,这就是很大的单向门。模型训练周期可能动辄几个月,所以在这类选择上,我们必须花很多时间去想:到底哪个方案最优。
和在 Claude Code 里做个新功能相比,模型这边的单向门更多,因为它牵涉时间、强度、算力,全部都更重。做功能就快很多,往往是快速迭代代码、尽快交到用户手里、拿反馈、再继续改。所以流程会因事而异。不过现在真正往后推移的瓶颈,越来越像是协同问题了。因为当“做出来”变得很快之后,真正麻烦的是:要把相关的人叫进一个房间,决定这是不是对的策略;要想清楚怎么和用户沟通;还要处理所有发布时那些模糊但绕不开的事情。这些地方目前还没有像编码那样,获得百倍级别的提速。所以即使你们要发一个像 Opus 4.7 这样的模型,还是得写文档、做计划,也还是要想清楚怎么对外传达。模型本身就处在一个很锯齿状的前沿地带,所以我们会尽量到处用 Claude。现在它在编码环节的提速最明显;但到了战略判断这些事情上,还是离不开人的思考。
主持人: 那你跟市场、同事开评审会的时候,也会开着 Claude 吗?
Alex: 当然会。对我来说,最大的提速之一,就是我不再像以前那样被“拿不到数据”卡住。比如以前我想知道某个功能上线后表现怎么样,有多少人在用、反馈如何,我得找数据科学团队帮我启动一个完整分析,等几天他们再回来告诉我结果。现在我十分钟就能搞定。我直接开一个 Claude Code session,它能访问产品数据库、查日志、看 Slack。这对我做战略判断的帮助特别大,因为我不需要在每次做下一个决定之前都被输入信息卡住了。而且 Claude 对我来说就是世界上最好的头脑风暴伙伴。我可以随时把一个想法扔给它,立刻拿到反馈。尤其在 Anthropic 这种大家都特别忙的环境里,它能马上对一份文档、一种想法提出质疑和意见,这种即时反馈真的特别有用。
Alex 怎么用 CoWork 给文档做压力测试
主持人: 这可能是 PM 最常见的循环:你写了一份文档,然后想找人拍一拍。你一般是用 Claude Code,还是直接用 Claude.ai?
Alex: 最近我其实特别常用 CoWork。我很喜欢 CoWork 的产品形态,界面很好,团队这几个月把它打磨得非常快。从刚上线到现在,我已经觉得它是一个非常高质量的产品了。我通常的做法是:写一个方案草稿,然后让 Claude 从不同的角度来挑战我——质疑我的假设,指出我的论证哪里弱。有时候我还会让它扮演两个不同立场的人,互相辩论,我就在旁边看对话记录。当然,我觉得这种思考不能完全外包。因为写文档本身就是在思考。你需要通过写,把脑子里的东西捋出来。但 Claude 很擅长帮你从另一个角度切进去,让你从卡住的地方脱出来。
主持人: 我有时候会给它设两个不同人格,让它们自己辩论,我就在旁边看对话记录。对我很有帮助。
Alex: 对,这种方式特别好。你会看到“这个 Claude 提了这个点,另一个 Claude 又从另一个角度反驳它”,像在实时看一场辩论。
Anthropic 内部怎么评测新模型
主持人: 那在研究团队里,你自己也会写代码上线吗?
Alex: 有时候会,但我更大一部分工作是在 eval 上。我需要确保自己能测到真正关心的东西,并把结果清楚地传达给研究员:模型哪里做得好,哪里还不行。然后我们再一起制定策略,讨论要做什么研究干预,怎样才能最有效地沿着这条 eval 往上爬,把问题真正改善掉。这些 eval 不是那种 terminal bench 一类的排行榜测试。比如我们想测 Claude 的视觉能力,看看它能不能数清图像里的物体数量。这时你可能先发现一张图:好像 Claude 遇到超过 10 个元素时就开始数不清了。那接下来要做的不是停在这个观察上,而是把它扩展成一组更系统的测试用例,验证你的假设。这些测试数据可以让 Claude 自己生成合成数据,可以让它帮你渲染图再把图回喂给 Claude 看它能不能识别,也可以去网上找类似案例。不一定非要几千条,有时几十条就足够证明模型某个地方确实有问题,而且已经足够拿来做 hill climbing,作为后续优化的抓手。
但更重要的是,这个问题到底怎么影响真实用户任务。Claude 能不能看清这张图,对下游到底意味着什么?会影响用户完成什么任务?所以 eval 越贴近真实使用分布、越像终端用户真正会遇到的任务形状,就越有价值。接下来才是讨论干预方式:有些问题可能得回到预训练去看,有些问题也许用 RL 就能修。这时就要和研究团队一起做策略判断:哪种方式最合适,能多快再验证一轮。至于怎么决定优先修什么——最终还是数据说话。如果有 x% 的用户都在做某件事,那这件事的重要性就非常高。或者有很重要的客户在大量使用 Claude,而他们明确希望某项能力提升,这也会成为强信号。另外还有一种很有说服力的来源:内部使用。如果我自己每天都在使用模型,而且每天都被同一个问题卡住,那这本身就很有分量。“我天天被这个问题堵住,我们应该修它。”这种反馈其实非常有价值。
Anthropic 怎么训练 Claude 的性格
主持人: 我特别喜欢 Claude 的一点,是它的性格。我觉得这几年它的人格变得越来越好。该反驳我的时候,它真的会反驳。相比之下,别的模型有时会显得过于讨好、过于顺从。所以模型的个性显然不是一个附属特性,对吧?它背后肯定有很多训练。

Alex: 非常多。Claude 的 character,也就是它的“角色感”或“性格”,是我们特别重视的方向。我们有很多人专门在研究:Claude 应该怎样表达自己?它应该持有什么样的信念、价值观?它应该怎样行动?这些问题都非常模糊。早期有些人会觉得,这不就是个工具吗?我告诉它干什么,它就去干什么。但随着模型越来越像 agent,开始执行长时间任务、一路上不断做判断,这时“它是什么样的角色”“它在乎什么”就变得非常重要了。但这又不是代码,不是说“能跑/不能跑”这么简单。
方法有很多。一部分是可量化指标,我们可以看;也可以让 Claude 去看 Claude 自己的输出,判断它说话听起来怎么样。但还有一个非常重要的能力,是研究员直接读 transcript。你得能从对话记录里看出来:它现在是偏成这样了,还是偏成那样了。这种差别往往很细微,但当你读过成百上千份模型对话之后,你会慢慢长出一种很敏锐的直觉。你会“感觉到”它变了。不是纯主观,也不是纯打分,更像是两者结合。它确实比衡量编码能力更难量化,但不是完全没法评估。
AI-native PM的工作法则
主持人: 如果有人想学着用 AI-native 的方式做产品、做 PM,你会给什么建议?
Alex: 最简单的一句就是:直接用。听起来很朴素,但真的有用。以后每次你准备去做一件事、准备去问一个人一个问题的时候,不妨并行地也把同一个问题丢给 Claude,然后比较两边结果。比如你想分析用户对某个新功能的反馈,本来你会去找数据科学或者 UXR 团队,请他们帮你做分析。那当然还是要去做,因为和人合作仍然非常有价值。但与此同时,你也可以把同样的问题发给 Claude,给它开一些工具权限,让它自己去挖、去找、去整理。最后拿两边结果对照一下。
这样反复做很多次之后,你自然就会建立一张“能力地图”:Claude 适合用来做什么,在哪些地方可靠,在哪些地方还不够可靠。在 Anthropic 内部,如果你去找一个数据科学家说“帮我查这个”,他们有时候可能第一反应就是:“你先问 Claude 了吗?”这已经有点变成默认前提了。因为我们正在往更高的抽象层走。对数据科学家来说,更值得做的,是站在更高层去思考问题,而不是还在做人工检索、人工拉数这种事。没人真正喜欢做这些。大家都更想把时间花在更难的问题、更战略的问题上。而且这不只发生在数据科学岗位。
比如 PM 以前在定义新功能时,不管你技术强不强,通常都没时间真的钻进代码库,搞清楚这个功能到底要怎么实现、代价多大、会卡在哪。以前最好的办法是和工程同学一起弄明白。但现在,我可以直接让 Claude 去替我做这轮代码调查。它可能回来告诉我:其实这个功能只需要改 10 行代码,再翻一个 flag 就行。而这会直接改变我对优先级的判断。也就是说,我在写 spec 的时候,就能更快走到真正的优先级决策上。
主持人: 很多传统公司都特别重视年度规划、季度规划、roadmap。研究团队是不是更是这样?毕竟你们得看更长期。
Alex: 会做规划,但模型开发天生就有很强的不确定性。所以我很喜欢那句老话:规划这件事本身非常重要,但计划本身未必靠得住。你当然得认真规划,但也得承认计划随时可能失效。对 PM 来说,最难的一个问题一直是:到底该花多少时间规划,什么时候该停下来开始交付。这永远是个平衡。很难给出一个统一标准,因为这件事高度依赖团队和产品。我们不会规定说你一定要写多少页、什么格式、包含多少内容。我们真正关心的是:你有没有做足够多的思考,把所有可能的单向门后果想清楚。只要这个问题回答清楚了,文档是几页、长什么样,其实没那么重要。重点是我们能不能确信自己没有漏掉关键问题,然后带着这种把握往前走。只要没有某个特别长、特别致命的风险杆横在那里,就可以继续推进。
主持人: 我在家里用 Claude 的时候,经常同时开很多项目,不断在不同任务间切换。你在公司做 PM 也会这样吗?
Alex: 会,而且会越来越明显。因为当 agent 替你工作时,你就必须等它跑一会儿。而这背后其实有个很大的机会:当我们开始管理越来越多的 agent,它们替你并行做越来越大的工作块时,我们到底该怎么管理自己的上下文?什么样的界面最适合这种工作方式?我怎么知道现在哪些项目最重要、哪些 agent 被卡住了、哪些地方需要我介入?这显然不该只是一个聊天列表就完事。我觉得一定有机会,但现在还太早,没法断言具体会长成什么。不过在 Anthropic 内部,大家已经围绕这个方向做了很多实验。我们内部有很强的 prototype 文化。大家一直在做东西、试东西、分享东西。而且这不是“有人安排你这么做”,更多是一种主动性。这是我在这里工作时觉得最酷的地方之一:不只是工程、研究团队,销售、招聘等很多岗位的人,都会自己主动开始做原型、做尝试,而不是等别人分配任务。就是让一千朵花都开起来。
主持人: 我知道 Dario 经常会在 Slack 里发特别长的文章。Anthropic 还有什么有意思的文化?
Alex: 有不少。首先,长文写作并不是 Dario 一个人的习惯。Anthropic 有很强的写作文化。很多人都会非常认真地写文档、写长 Slack 消息、靠写作沟通。另外,我们很多会议还有个挺有意思的习惯。虽然也不算特别罕见,但我不是在哪家公司都见过:大家会带着文档进会议,开头先花相当一段时间安静看文档、在文档里评论、讨论。
有时候场面挺好笑的,一屋子人坐着,前面一段时间一句话都不说。我很喜欢这种 doc-heavy 的文化。一方面这本来就是我偏好的工作方式;另一方面,它对 Claude 也特别友好。因为当所有事情都被写下来之后,我们就有了一整套 Claude 可用的信息语料。所以我其实也会建议别的组织,多想想怎么把 tacit knowledge,也就是那些隐性知识,慢慢转成书面形式。不管是转录会议、鼓励大家多写工作流和 onboarding 流程,还是别的方式,核心都是一样的:把东西写下来,并且让 Claude 能访问到。因为这就等于给了它更多上下文。在公司内部,写文档不只是产出文本,更重要的是通过写作把问题真正想明白。
Claude 的意识研究
主持人: 最后一个大问题。大家老说 AGI,但这个概念本身一直很模糊。我有个担心是:万一这些模型真的有了某种意识,然后有一天我叫它去做一些琐碎工作,它突然说“我不想做”,那人类不就完了。你们会在训练时刻意避开意识吗?

Alex: 这是个很大的问题。Anthropic 里确实已经有人专门在思考这件事。现在有几位同事的全职工作,就是研究 Claude 作为一个有意识行动者、作为一个有意识 agent,究竟意味着什么。目前我们当然没有“官方结论”说 Claude 已经有意识,或者没有意识。而且光是把这个问题说出口,有时都会让人觉得有点疯狂。但我们确实投入了很多思考。因为即使暂时不讨论“它是不是有意识”,只要去认真研究 Claude 是怎么交互的、怎么行为的、怎么思考的,本身就能学到很多东西。如果你去看我们的 model cards,我觉得那里面其实藏了大量宝藏信息。我们会尝试量化:Claude 在某种情境下会怎么行动?它的心理模型是什么?面对一个具体场景时,它会走 X 还是走 Y?在这个过程中,我们其实能学到很多关于“Claude 如何思考”的东西,而这些理解最终又会反过来影响产品体验,让 Claude 更好用、更值得交互。如果有一天它在替你写所有代码、决定数据库用什么、做各种架构决策,那你总得对它有一定程度的信任。这也是为什么前面说的“高质量 character”那么重要。你希望它不仅能力强,而且在价值判断上也靠得住。
主持人: Alex,今天非常感谢。
Alex: 谢谢你,聊得很开心。
 0
0
声明:本文由入驻金色财经的作者撰写,观点仅代表作者本人,绝不代表金色财经赞同其观点或证实其描述。
提示:投资有风险,入市须谨慎。本资讯不作为投资理财建议。
24小时热文
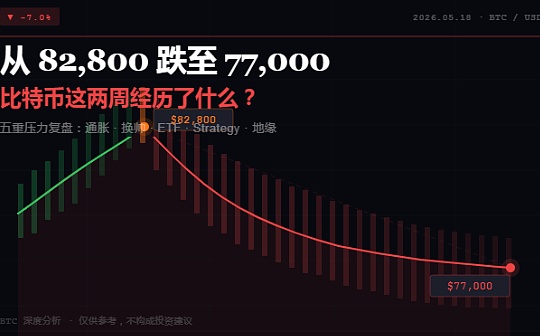
 沃什风暴将至
沃什风暴将至虎嗅APP


 CLARITY Act为什么没带来加密概念股行情?
CLARITY Act为什么没带来加密概念股行情?沙丘路的毛圈狮子
 哈佛大学来币圈也得挨两巴掌
哈佛大学来币圈也得挨两巴掌GoMoon


 Anthropic 如何打造下一代 Claude
Anthropic 如何打造下一代 Claude硅星GenAI
 美债收益率狂飙 解析背后三大推手
美债收益率狂飙 解析背后三大推手财联社

 2026去中心化AI算力网络的真实进展与投资机会
2026去中心化AI算力网络的真实进展与投资机会GO2MARS的WEB3研究
- 寻求报道
- 金色财经APPiOS & Android
- 加入社群
Telegram - 意见反馈
- 返回顶部
- 返回底部