

 Android & iPhone
Android & iPhone解读Anthropic新作:如何构建高效的 AI 人机协作团队

十四君
刚刚
在6.24日,Anthropic 官方博客再发新文章 Building effective human-agent teams,作者 Kristen Swanson。
文章的核心点在于讨论AI 团队级协作的范式,正在发生转移,从"一个人对一个聊天框(哪怕是背后站在很多agent)",转向"一群人和一群 agent 共享同一个工作空间"。
笔者此篇会在转述原文核心观点的基础上,结合AI agent 落地经验给出脉络梳理与综合性思考。
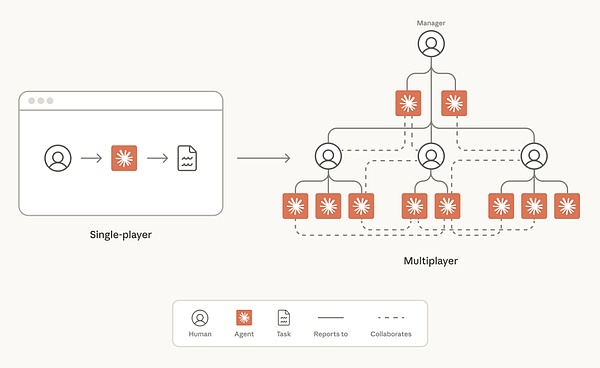
一、主旨:AI协作团队正在变成"联机模式"
过去,使用 AI 一直是一种"单机(single-player)"体验——一个人和 agent 协作,完成个人任务。
而现在新的模式是,人类和 agent 可以在同一个工作空间里协作,服务于一个团队共享的目标。
工作开始更像一场"多人联机游戏(multiplayer game)":由人类团队制定策略,由 Claude 来执行。
总之,就是共享目标、共享上下文、尤其是共享工作空间。
如下图,向右侧的复杂工作模式的转换正在发生:
而实现这一转变的是 Anthropic 新产品 Claude Tag,一种让 Claude 进驻 Slack 等团队协作工具、像团队成员一样被 @ 和被指派的形态。
所以,这篇文章不是纯理论,而是 Anthropic"本身产品在推动的方向
二、什么是"多人 agent" 协作问题?
原文给"multiplayer agents"下的定义是:同时与许多不同的人类协作的 AI 模型。
它和我们熟悉的普通 agent 有相同之处,也有关键区别:
相同:它有自己的记忆和技能(skills)。
不同:它有自己的凭证(credentials),
并且"living where work happens"——活在工作真正发生的地方。
在 Anthropic,那个地方就是 Slack 这样的团队协作工具。
这个"有自己的凭证、活在团队频道里"的设定非常重要。
它意味着 agent 不再是借用某个人的账号、在某个人的私有会话里干活,而是一个具备独立身份的团队实体:它能被全团队看到、它的产出对所有人可见、它读取的上下文是团队级别的而非个人级别的。如下图,变成你办公软件中的一员。
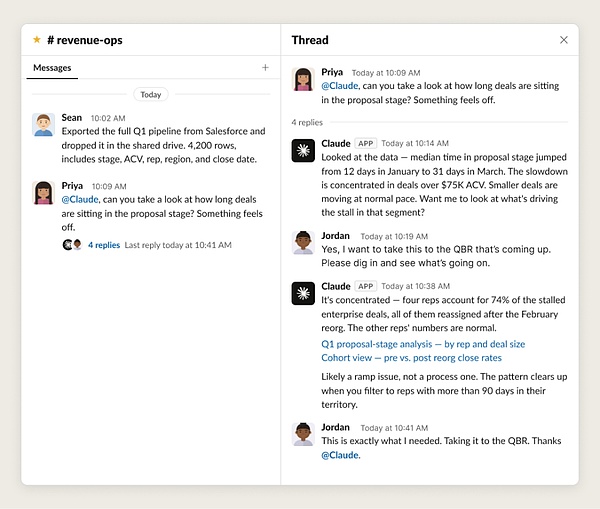
那要让 agent 能在团队频道里"高效参与",需要一组特定的底层能力(比如Claude Tag 这样的产品形态)+专门设计的持久记忆,身份独享,信息来源等机制。
除此之外,光有技术能力还不够,要让人机团队"成功"得靠的是一套工作方式和共享规范。
所以文章的后面四条经验,讲的全部是设计AI 团队的 "规范"的经验
三、AI agent team 的四条经验
经验一:改革信息管理,给 agent 尽可能广的上下文
Anthropic 认为不要逐个文档、逐个频道地决定哪些信息对 agent 可见,而是用清晰定义的安全边界(security boundaries),一刀切地作用于整个 Slack 工作空间、会议转录、文档库。
原文专门点名了那种日常折磨:"这个频道该设公开还是私有?这份文档能不能分享给那个人?这个 agent 能不能看那条消息?"
应该在在边界之内,上下文对每一个团队成员——无论是人还是 AI对是可见的,甚至AI可以去仿照人一样,申请文档的权限。
这一招的精妙在于它同时解决了两个问题:
1.扩大了 agent 和人能拿到的上下文;
2.消除了"逐项分享"带来的决策疲劳。
权限开放回报是实打实的,不再有信息透传的损失,而且因为 agent 读文本的速度远超人类,它们能"routinely surface relevant work that humans would otherwise have missed"(常常翻出人类本会错过的相关工作)。
在笔者看来,这本质是组织文化与权限机制的转移。
"默认内部公开"对很多公司来说是要动筋骨的文化变革。
因为Anthropic 一开始就是一家高度信任、信息扁平的公司,所以他并不能理解那种大公司病,尤其是传统行业中,跨级别的信息差,形成的资源差。
而且对于很多强合规、强信息隔离(金融、医疗、跨法域)的组织,"工作空间级一刀切"未必可行。
所以真正可应用的是它背后的精简审批机制,比如只要agent 在某个群,就天然可读该群有权限的文档,即使有权限管控,也可以天然的批量管理,而非先给文档,再安排质量。
经验二:每个人/agent 有明确角色与工具
原文的画面感很强:人机团队共享一份花名册、一套产物、一个工作空间。
在这之上,agent 各有分工:
一个 agent 拥有某项目的数据分析;
另一个持有并执行设计规范;
第三个负责研究综合(research synthesis)。
项目启动时,人类先和 agent 聊一聊,决定怎么分配角色、人和 agent 如何协作。
然后产出下图这样的角色与规则+介入时机的组合。

角色明确之后,一个 agent 甚至可以"spin up"(拉起)其他 agent,确保每个具体任务都交给那个拥有正确记忆、正确访问权限的 agent 去做。
关键是工具配齐:做数据分析的 agent 可能需要 BigQuery 访问权,做 QA 的 agent 可能需要 Playwright MCP。
人类持有只有人类能持有的角色,确保让人类判断被用在最重要的决策上。
笔者认为:这也是 Anthropic 既往研究机制工作流程的架构。
用一个 lead agent 协调全局,把任务委派给并行运行的专门化 subagent。这类机制确实很实用,质量指标是几乎翻倍的(高出 90.2%),虽然成本增长15倍的Token。不过,"多 agent 更强"不是普适结论,而是"在某类任务上、以可观的算力代价换来的提升"。
尤其是广度优先、可并行的工作中,并且由于更强的交叉验证机制,所以信息准确度更好。
并且还要精细设计,做好任务分解与角色隔离,而不是简单地"多堆几个 agent"。
否则就又是新一代亩产1万八千斤的误解了。
这很多观点也在上篇文章里如何用 Claude 的 Dynamic Workflows 做深度研究
经验三:设定北极星角色,让 agent 主动解决问题
原文区分了两类 agent:一类只是"完成被指派的任务",而最重要的那类会主动提出新项目和新工作流。
后者通常出现在一个已经具备丰富上下文、清晰角色的团队,再加上一条额外的指引——北极星(north star)。
北极星负责帮团队判断"哪些任务和工作流才是对的"。
原文强调了几条纪律:
•北极星永远由人类设定,并扎根于公司的使命与业务目标;
•北极星一旦被清晰地写下来,人类把它分享给团队里的 agent;
•然后——这一步很关键——人类挑选哪些 agent 应当主动提议新工作流。
假定一个运营驱动的产品和公司,那就应该让运营角色来成为主导agent,而非是产品驱动,或者技术驱动,财务驱动。
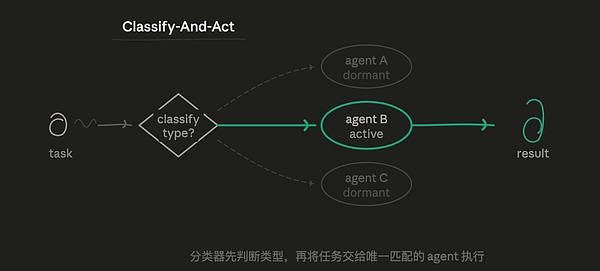
就像如何用 Claude 的 Dynamic Workflows 做深度研究中的 路由模式(Classify-And-Act),先由一个 agent 分辨任务类型,再把任务分发给最适合的专门 agent 去做。
笔者认为,之前看 Anthropic 有不少文章,都有提现出在他们眼中什么是 agent ,什么是 workflow?
前者则"动态主导自己的流程和工具使用,掌控如何完成任务"。
而后者 是"通过预定义代码路径编排"的确定性系统;
所以要做ai团队,是应该给 agent 一条北极星而非一张任务清单,正是在有意识地把系统从 workflow 推向 agent。
一个有目标的Team会带来一些创造力,而不是在有限的范畴内没事找事。
当然,我们现在做的很多ai team,其实是程序化或者ai化workflow,这已经能解决很多问题了,如果我们后续需要的是创意性,自驱的,有主动解决问题能力的,则必须要设计这样agent式的team。
经验四:让agent随时间成长
这里官方的数据非常让我惊讶,他说:Anthropic 的工程师已经能让团队里的 agent 独立处理 500 个 bug 修复——但紧接着强调:"things certainly didn't start off that way(一开始绝不是这样)。"
它把 agent 类比成新入职的人类同事:需要多轮反馈才能把"任务到底怎么做最好"这种隐性知识外显出来。
用户必须反复用各种任务去试探 agent,才能摸清它的能力边界、如何清晰描述目标、它需要哪些 skill 文件、什么 prompt 最能引出期望行为。
原文还特别提醒一个容易被忽视的点:模型会升级,任务要重测——prompt 可能要重写,过去有用的护栏(Harness)可能反而会束缚一个更聪明的模型去寻找更有创造力的解法。
这条经验里含金量最高的,是关于验证(verification)的论述:
> 我们发现,最好的长周期 agent,在交给人类看之前,有许多种方式来验证自己的工作。
代码有测试,这是当然的;
但大多数其他工作同样可以被验证:技术文档可以套用评分量规(rubric)和风格指南(style guide);
当人类设定好标准、并确保交给 agent 的所有工作都可被审查时,质量就能保持、不偏离初衷;
此外,可以让一个 agent 干活、另一个 agent 检查——这就是常说的 "Doer-Verifier"(执行者—验证者)agent harness。
原文有个完整案例:某位工程负责人接手一个积压(backlog)很重的新团队,他叫上几个人 + 几个 agent 一起梳理优先级。
一组 agent 通读所有积压项、判断是否有人在做、给无主项打复杂度分;
另一组从清单里筛出中低复杂度项、直接产出代码改动。
起初,人类审查 agent 的每一个决策,并标出需要人介入的那些;然后,人类"教会"agent 把这类决策直接抛给人类,确保有艰难权衡的决定永远有"human in the loop"。
并且每周,团队还让 agent 编一份包含"经验与失误(lessons & missteps)"的周报,让 agent 记住错误、避免重犯。随着时间推移,负责人能交给 agent 越来越复杂的改动,自己花在日常指导上的时间越来越少,如下图:

像极了养聪明龙虾的过程。
最后一段是全文我最欣赏的一处洞察——当 agent 变得更独立之后,负责人开始教 agent 把"人类注意力"当作稀缺资源来对待:
比如把问题批量化,让人一次性回答,重复关键上下文,让人快速进入状态,限制一次性丢给人的事项数量。
有些人甚至专门设一个 agent,唯一职责就是决定如何批处理、并只把最重要的沟通上升给人类。
另一些人则给 agent 设"每天最多做多少工作"的护栏——这样人类才来得及有意义地参与,并且保住对自己重要的技能不被荒废。
笔者认为,这些经验是整篇文章在"人机关系"上最深刻的地方。
第一,Anthropic的思想里认为:有效的监督不是审批每一个动作,而是"处在能在关键时刻介入的位置"(being in a position to intervene when it matters)。
第二,把"人类注意力"显式当作稀缺资源去优化,是一个被严重低估的设计原则。大多数关于 agent 的讨论都在优化"agent 的能力",而效率实际的瓶颈已经是"人的认知带宽"了。
第三,Harness驾驭工程是在人机团队里,应该完全模拟高效团队的方式,毕竟有些好马,确实不需要缰绳,只需要目标。
四、人机协作时代,会无情地放大原团队的组织质量
这篇文章最诚实、也最容易被忽略的一句话出现在结尾:
他说,上面这4条经验其实并不新颖,早在AI出现之前就存在了,好的团队要有强有力的北极星、清晰的角色、扎实的文档、共享的质量标准、从错误中学习的空间,都是我们几十年来就熟知的健康团队习惯。
而AI agent team 只是让这些基本功变得更加重要。
如果没有合理的机制建设,AI 不会自动让团队变强,甚至会造成挤压,最终带来混乱,比如:
上下文涣散的团队(如靠信息差来管理),接入 agent 后只会更涣散(信息隔绝越大,产出越偏离);
角色定位混乱的团队,agent 只会复制混乱,互相工作职责紊乱,决策者判断源失真。
没有验证文化的团队,agent 的错误会以更快的速度规模化,AI代码的速度已经远超过人的CR速度。
因此,笔者认为,"从这波 agent 红利里拿到最多的团队,也是那些最有意识地去践行这些基本功的团队。"
对正在押注 AI agent 的组织来说,这篇文章给出的真正功课,或许不在"怎么用 Claude",而在回头把自己团队的上下文、角色、目标与质量标准这四件旧事,认认真真地重做一遍。
 0
0
声明:本文由入驻金色财经的作者撰写,观点仅代表作者本人,绝不代表金色财经赞同其观点或证实其描述。
提示:投资有风险,入市须谨慎。本资讯不作为投资理财建议。

24小时热文



 强美元、加息预期与AI虹吸
强美元、加息预期与AI虹吸中信证券研究
 Anthropic推出Claude Tag为什么先帮竞品涨了注册?
Anthropic推出Claude Tag为什么先帮竞品涨了注册?区块律动BlockBeats







- 寻求报道
- 金色财经APPiOS & Android
- 加入社群
Telegram - 意见反馈
- 返回顶部
- 返回底部